尺度作成のヒントページ
(SPSSと
SAS)
Ver 10.4(2010.7.15)
質問紙などで尺度を作成したあとの基本的な処理についてのヒントです。
おおよそ,処理の順序に近く書いてありますが,このままの順序で実施するのではなく,作成する尺度によって必要なものが異なりますので,適宜取捨選択して下さい。 特に因子分析はあくまで例示ですので,他にも様々な分析方法がありますので,必要に応じて使い分けて下さい。
SPSSそのもののトラブルシューティングとしては
SPSS勝手にFAQなども参考にして下さい
基本データ構造(例示用)
各項目は1~6点の6件法でコーディングされているものとする
回答者
番号 | 性別 |
項目1 | 項目2 | 項目3 |
項目4 |
| 1 | 女 | 6 | 1 | 1 | 5 |
| 2 | 男 | 1 | 2 | 5 | 1 |
| 3 | 男 | 2 | 4 | 3 | 2 |
| 4 | 女 | 3 | 6 | 5 | 6 |
| 5 | 女 | 1 | 2 | 2 | 3 |
【1】データを入力する
まず,文字データ(例では男女など)は,数字にコード化しておいた方が後々便利。
(女=1 男=2など)
以下のような方法のいずれかで入力するとよい
- SPSSから直接入力する
SPSSを立ち上げると出てくるデータエディタに直接入力する。他の方法のような変換処理をしなくてよいのは便利だが,どうしても重たくなるので,大量データには不向き
- Excelなど表計算ソフトから入力する
表計算ソフトが慣れている人ならこれでも使える
SPSSではファイル(F)-開く(O)でワークシートを指定する
(SPSS9.0以前の場合は,通常のExcelブック形式のワークシートをSPSSが読み込めないので,Excel Ver4形式のワークシート(xls)で保存する)
- テキストエディタから入力する
データ数が多い時は,これが一番早い。SASなど他のソフトともデータを共有できるのが強み
データは拡張子*.TXTまたは*.DATにしておくと,SPSSで読み込む際に便利
ただしWindowsの「メモ帳」は容量が小さいのでデータ入力には使えない。普通はスペースやカンマ区切りなどで入力するが,固定長で連続で入力した方が,実は早い。
(SPSS8.0ではコマンドシンタックスを用いないと読み込めない。SPSS9.0以降では固定長書式をメニューで読み込めるようになったが,コマンドシンタックスの方が後々何度も使えるので便利)
シンタックスの書式例はSPSS勝手にFAQ参照
欠損値についてはSASではピリオドが用いられるが,SPSSでは欠損値として読みとらないので,予め別の数字(データで使わない)を入れておき,SPSSの中で「変換-データの再割り当て」で,この数値を「システム欠損値」に書き換えること。
(この書き換えを忘れると,欠損値が実際の値として計算されてしまい,結果がおかしくなる。)
なお,SASデータセット(バイナリ形式のもの)を直接読み込む場合は,コマンドシンタックスでGET SAS DATA文を用いる(GET SAS DATA文の具体的使い方はヘルプのSyntax guide参照)
最近は少なくなったが,ワープロ専用機からテキスト出力する場合など,ファイル末尾にEOF(^Z)制御コードを書き込んでしまうものがある。この制御コードはしばしば誤動作の原因となるので,テキストエディタなどを使ってEOFコードはなるべく除去しておく方が安全。
【テキストデータ読み込み】[ファイル-開く]メニューの場合(SPSS10以降)
読み込むデータ
NO AGE X1-X5
↓ ↓ ↓
001 20 12121←1人目の1行目
123156 15111←1人目の2行目
Y1-Y6 Z1-Z5
二人目以降↓
002 21 12321
1311 51222
: : : :
固定書式の場合(どのケース(回答者)でも同一変数は同一カラムになっている場合)
自由書式の場合(カンマなどデータ区切り文字で区切られ,カラムの位置は固定でない場合)
※HALBAU形式データは,先頭1行を削除することで自由書式として読みこむ。
【固定長テキストデータ読み込み】コマンドシンタックスの場合
読み込むデータ
NO AGE X1-X5
↓ ↓ ↓
001 20 12121←1人目の1行目
123156 15111←1人目の2行目
Y1-Y6 Z1-Z5
二人目以降↓
002 21 12321
1311 51222
: : : :
固定長書式のデータをFORTRAN流のフォーマット書式で読み込む例
(一人あたり二行にわたっているケース)
とっつきにくいようだが慣れてくるとこの方がデータ管理は断然楽
DATA LIST
FILE='C:\MyDocument\Data.dat' FIXED RECORDS=2 TABLE /
NO,AGE,X1 TO X5,Y1 TO Y6,Z1 TO Z5
(F3.0,1X,F2.0,1X,5F1.0 / 6F1.0,1X,5F1.0) .
EXECUTE.
RECORDS= は,ケース一人当たりが使う行数(この例では一人2行)
1行目のNO,AGE,X1~X5および
2行目のY1~Y6,Z1~Z5を()内の書式(太字)で読み込ませる
X1 TO X5 などの[TO]は連続した変数並びの時の省略記法('~'に該当する)
【FORTRAN書式のルール】
Fは実数,Xは読み飛ばし(ブランク箇所など),/は改行
[#].[#]は[全桁数].[小数点桁数]を意味する。よって
F3.1....小数点を含め全体で3桁で,内 小数点以下桁数1のもの(「1.5」など)
F1.0....1桁で小数点以下がない=1桁整数
5F1.0...1桁の数値が5回連続して並んでいる
1X...1桁読み飛ばす(実際にはその場所にデータがあっても,X指定された列は読み飛ばされる)
例
F3.0,1X,F2.0,.....3桁整数,ブランク1,2桁整数 というデータ並び
/6F1.0,1X,5F1.0....改行して1桁整数が6連続,ブランク1,1桁整数が5連続
変数のリスト(NO,AGE....の部分)とFORTRAN書式の並びは合致していなければエラーになる
データ入力後のSPSSデータエディタの状態
| NO |
SEX |
V1 |
V2 |
V3 |
V4 |
| 1 | 1 | 1 | 6 | 1 | 1 | 5 |
| 2 | 2 | 2 | 1 | 2 | 5 | 1 |
| 3 | 3 | 2 | 2 | 4 | 3 | 2 |
| 4 | 4 | 1 | 3 | 6 | 5 | 6 |
| 5 | 5 | 1 | 1 | 2 | 2 | 3 |
- 変数はなるべく短い記述の方が後々楽
- 変数名は「半角英数」を使った方がよい
(SPSS8以降は変数名に全角文字や日本語も使えるが,後々使いにくいのでやめたほうがよい)
- 変数内容は「ラベル」に書き込むのがコツ
(SPSS10以降では「変数ビュー」タグ,Ver9.0まではグレーの欄の変数名をダブルクリックすると変数指定用画面が出てくる)
- 欠損値の指定を行う
変数ビュー画面の「欠損値」をクリックし,「個別の欠損値」に,欠損値指定の値を入れる
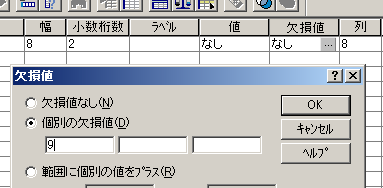
例)ある変数の欠損値に[9]を指定する
同じ欠損値を多くの変数に指定する場合は次のようなシンタックスを実行する方が簡単
missing values gakunen,seibetu,v1 to v50 (9).
execute.
例)gakunen,seibetu,およびv1からv50までの欠損値を[9]に指定する
- あるいはシステム欠損値に変換することもできる
※ただしSPSSのシステム欠損値はExcel形式で保存した場合#NULL! となってしまうので,Excel形式で保存する場合はシステム欠損値への変換は避けた方がよい
- [変換]-[値の再割り当て]-[同一の変数へ]
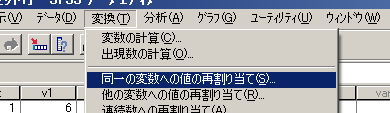
- 変換する変数を左側のボックスのリストから選んで
- 「今までの値と新しい値」をクリック
- 「今までの値」欄に,欠損値とみなしている数値を入れる
- 「新しい値」欄は「システム欠損値」の左脇の○をクリック
- 「追加」ボタンをクリック(「旧→新」欄に 「(今までの値)→SYSMIS」が表示される)
- 「続行」ボタンをクリック
- 「OK」ボタンをクリック
【2】項目得点を見る
項目得点の度数分布や基本統計量から,得点が偏ったり,分散が小さい項目がないかチェックする
- [分析]-[記述統計]-[度数分布表]で度数分布
- [分析]-[記述統計]-[記述統計]で平均値や標準偏差
オプション内容をよく見て,不要な統計量は出力させないのが「通」のやり方
※逆転項目の処理
SPSSでは以下のようにする
6件法で取りうる得点が1~6点
素点が変数v,変換後の」得点がv1の場合
compute v1=7-v.
(とりうる得点の最大値+1から素点を減じる)
(ただし,多くの場合は,因子分析などを行ってみないと,どの項目を逆転項目とみなすかは確定できないので,確定するまでは,逆転しない得点を用いた方がよい)
【3】因子分析
因子分析はいろいろな方法がありますので,各自試してみて下さい。下は一例です
因子分析の基本的な考え方については
松尾太加志・中村知靖(2002)誰も教えてくれなかった因子分析:数式が絶対に出てこない因子分析入門北大路書房ISBN4-7628-2251-5 などが参考になります
- [分析]-[データの分解]-[因子分析]
- 因子抽出:方法=「主因子法」「最尤法」など
(デフォルトの「主成分分析」は因子分析では選択しないよう注意)
- 分析=相関行列, 抽出の規準=最小の固有値, 表示=回転のない因子解, 収束のための最大反復数=100~200くらい(デフォルトの25は小さすぎる)
などを設定して「続行」
- 回転:「バリマックス」あるいは「プロマックス」回転が一般的,表示=回転後の解
,収束のための最大反復数=100~200くらい
- 得点:何もチェックしない(ケース各個人の因子得点がほしい場合は「変数として保存」にチェック)
- オプション:欠損値:ペアごとに除外(リストごとだとnが小さくなってしまう)*
ありがちなエラー
- 相関行列の計算などで「この値は正値行列ではありません」と出て停まってしまう
(逆行列が計算できないなどデータに問題がある時のエラー)
→項目数よりケース数が少なくないか?
(ケース数がぎりぎりだと欠損値によって実質的なケース数が減ってしまえば,同じエラーになる)
- 共通性の推定値が1を越えてしまいエラーになる
→いわゆる「Heywoodケース」と呼ばれるもの
データや因子数が不適当な場合などに生じやすくなる
→変数読み込みの際のカラムがズレていたり,関係ない変数まで分析に投入してないか?
(Heywoodケースについては上記の参考文献または「SAS/STATソフトウエアユーザーズガイド」の因子分析のページ参照)
[コマンドシンタックス](ECONVERGE(0.000001)だけはメニューでは指定できないので別途指定する)
FACTOR
/VARIABLES v1 TO v4 /MISSING PAIRWISE /ANALYSIS v1 TO v4
/PRINT INITIAL EXTRACTION ROTATION
/CRITERIA MINEIGEN(1) ITERATE(200) ECONVERGE(0.000001)
/EXTRACTION PAF
/CRITERIA ITERATE(200) ECONVERGE(0.000001)
/ROTATION VARIMAX
/METHOD=CORRELATION .
【4】上位・下位分析(GP分析)
※GP分析では,計算内容を少しずつ変えながら何度も似たような計算を行うので,メニューモードで一度作成した計算をもとに,「コマンドシンタックス」を使う方がよい
※基本的に同一次元の尺度内で分析しないと意味がない
※逆転項目は,以下の説明にあるように,得点を逆転して合計すること
- 合計点を算出
[変換]メニュー-[変数の計算]を選択
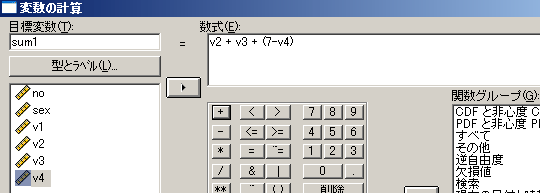
- 「目的変数」欄=新たな変数名(sum1)
- 「数式」欄=当該の項目以外の全項目得点を合計するための式を書く
- 例)sum1=v2+v3+(7-v4)
これはsum1という新変数を作りv1以外の残りの各項目の合計点を入れるという意味
- 逆転項目は (とりうる最大値)+(とりうる最小値)-数値
(上の例ではv4が逆転項目。6+1-実測値で逆転している)
※即実行する場合は「OK」,コマンドシンタックスを作成する場合は「貼り付け」
- 1で作った合計点について上位群・下位群の得点範囲を求める
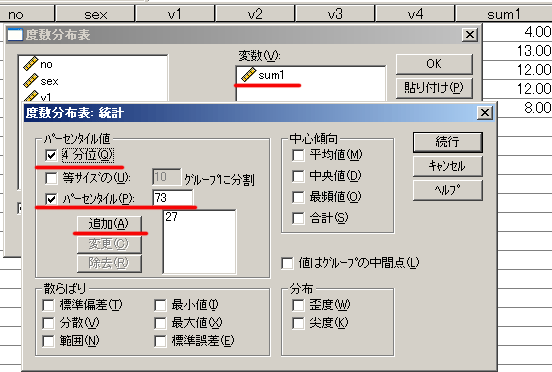
[分析]-[記述統計]-[度数分布表]
・変数には今作った「sum1」を指定
・「統計」-「四分位」にチェック
また下位群27%,上位群73%など細かい割合を指定したい場合は「パーセンタイル」で指定し「追加」
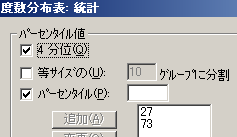
その場合は,上位,下位両方とも「追加」してから実行する
計算結果

例)このデータではsum1は3点(1点×3項目)から18点(6点×3項目)までが取りうる値の範囲である(第1項目を除いた合計なので4項目中3項目の合計となる)
上の「統計量」から上下25%の場合,下位群は3から6,上位群が12.5-18点の範囲となる
(下位27,上位73%の場合それぞれ27,73パーセンタイル値をみる)
- t検定で用いるための「グループ化変数」を作成する
(下位群の人=1,上位群の人=2となるような変数を作成する)
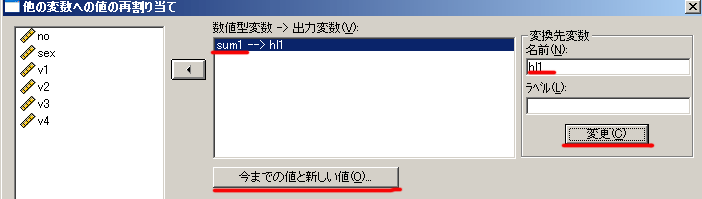
(1)[変換]-[値の再割り当て]-[他の変数へ]
(バージョンによっては[変換]-[他の変数への値の再割り当て])
(2)sum1を左端の一覧から選択し,右のボックスに移動
変数ボックスにsum1--->? と表示される
(3)変換先変数欄に新しい任意の変数名(たとえばHL1)と書き「変更」を押す
変数ボックスにsum1--->HL1 と表示される
(4)[今までの値と新しい値]をクリック
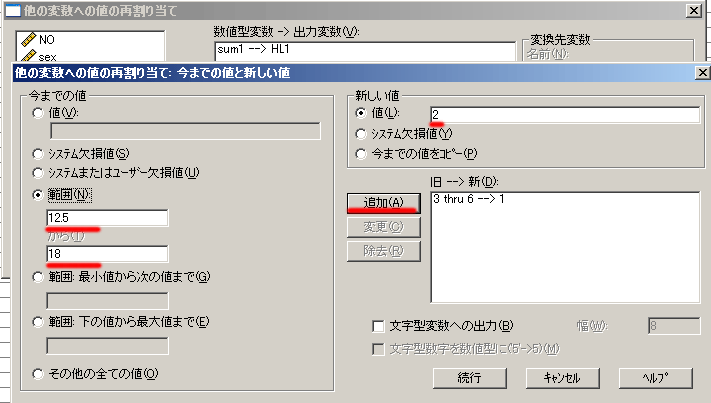
・「今までの値」の「範囲」を選択しボックスに値の下位群の範囲を入れる(3 から6)
右側「新しい値」の四角い欄に1と書いて下の「追加」を押すと
「旧→新」欄に「3 thru 6 -->1」と表示される
・次に上位群についても同じように
左側の「範囲」を選び,上位群の範囲(12.5から18)を記入し,「新しい値」の値欄に2と記入し「追加」
「旧→新」欄の二行目に「12.5 thru 18 -->2」と表示される
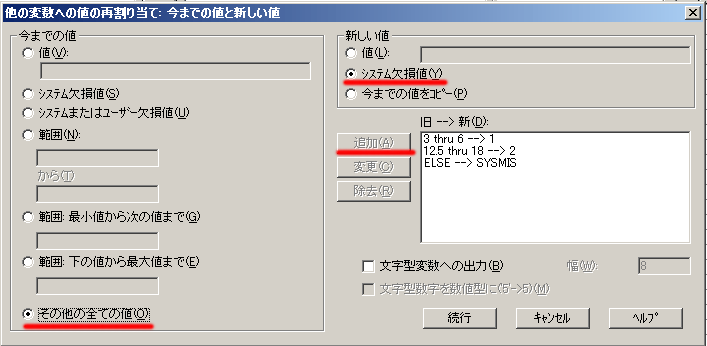
今までの値 その他すべての値をび,「新しい値」欄で「システム欠損値」を選択して「追加」を押す
「旧→新」欄の三行目に「ELSE -->SYSMIS」と表示される
終わったら「続行」ボタンを押す
最後に[OK]を押す
これで下位群データはHL1が1 上位群データはHL1が2にセットされる
その他中間群ではHL1はシステム欠損値になる
ここまでの作業でのデータエディタの状態
| NO |
SEX |
V1 |
V2 |
V3 |
V4 |
SUM1 |
HL1 |
| 1 | 1 | 1 | 6 | 1 | 1 | 5 | 4.000 | 1.00 |
| 2 | 2 | 2 | 1 | 2 | 5 | 1 | 13.000 | 2.00 |
| 3 | 3 | 2 | 2 | 4 | 3 | 2 | 12.000 | . |
| 4 | 4 | 1 | 3 | 6 | 5 | 6 | 12.000 | . |
| 5 | 5 | 1 | 1 | 2 | 2 | 3 | 8.000 | . |
- 上位群と下位群の間で,t検定を行う
[分析]-[平均の比較]-[独立したサンプルのT検定]
「検定変数」に従属変数(例でいえばv1)
「グループ化変数」に独立変数(HL1)
「グループの定義」ボタンをクリックしグループを示すグループ化変数値(例では1と2)を入れて「続行」
(ちなみにこの数値例では,データ数が少なすぎてn=1となってしまうためt検定は出来ない)
※v2,v3,v4についても同様にt検定を行う
※調べたいすべての項目について,先に四分位数および上位群・下位群まで求めてしまってから一度に検定した方が早い
※以上の操作で「OK」の代わりに「貼り付け」を選択していくと「コマンドシンタックス」に作業手順がSPSSのプログラムとして記録されるので,類似の作業を繰り返して行う場合には,いちいちメニューから実行するよりも便利
上記作業のコマンドシンタックスは以下の通り
COMPUTE sum1 = v1+v2+v3+(7-v4) . ←←←v4は逆転項目なので(7-v4)にする
::::
(全項目について)
::::
COMPUTE sum4 = v1+v2+v3.
FREQUENCIES
VARIABLES=sum1
/NTILES= 4
/PERCENTILES= 27 73
/ORDER ANALYSIS .
FREQUENCIES
VARIABLES=sum4
/NTILES= 4
/PERCENTILES= 27 73
/ORDER ANALYSIS .
::::
(全項目について)
::::
ここでいったん実行
RECODE
sum1
(3 thru 6=1) (12.5 thru 18=2) (ELSE=SYSMIS) INTO HL1 .
::::
(全項目について)
: : :
RECODE
sum4
(3 thru ?=1) (? thru 18=2) (ELSE=SYSMIS) INTO HL4 .
↑「?」には上で求めた四分位数が入る
T-TEST
GROUPS=HL1(1 2)
/MISSING=ANALYSIS
/VARIABLES=v1
/CRITERIA=CIN(.95) .
::::
(全項目について)
: : :
T-TEST
GROUPS=HL4(1 2)
/MISSING=ANALYSIS
/VARIABLES=v4
/CRITERIA=CIN(.95) .
::::
(全項目について)
::::
合計を算出するとき v1+v2+v3ではなくsum(v1 to v3)のような書式も可能だが,欠損値があると,欠損値以外の数値だけの合計を求めてしまうので,ここでは不適切
【5】項目得点と尺度得点の相関(IT分析)
当該項目を除いた項目得点の合計とv1...v4の相関を求める
※基本的に同一次元の尺度内で分析しないと意味がない
※逆転項目は,GP分析と同様,得点を逆転して合計すること
- 合計点を算出
データメニュー-計算を選択
- 目的変数=新たな変数名
- 数式=見たい変数を除いた他の変数を合計する式を書く
- ex)sum1=v2+v3+(7-v4) これはsum1という新変数を作り各変数の合計点を入れるという意味
(sum1は項目1(v1)と尺度得点との相関を見るために,v2~v4の合計点を求めたもの
v2の分析ではv1,v3,v4を合計する)
- 逆転項目は (とりうる最大値)+(とりうる最小値)-数値
(上の例ではv4が逆転項目。6+1-実測値で逆転している)
(ここまでの具体的な方法はGP分析の欄参照)
- 相関を求める
- [分析]-[相関]-[2変量]
- 相関係数:ふつうはPearsonを選択
[コマンドシンタックス]
COMPUTE sum1 = v2+v3+7-v4 .
COMPUTE sum2 = v1+v3+7-v4 .
COMPUTE sum3 = v1+v2+7-v4 .
COMPUTE sum4 = v1+v2+v3 .
CORRELATIONS
/VARIABLES=v1 sum1
/PRINT=TWOTAIL NOSIG
/MISSING=PAIRWISE .
: : : :
: : : :
CORRELATIONS
/VARIABLES=v4 sum4
/PRINT=TWOTAIL NOSIG
/MISSING=PAIRWISE .
【6】信頼性係数
[分析]-[尺度]-[信頼性分析]を選択
モデル=アルファでアルファ係数が求まる。その他,折半法,Guttman法,平行法などが選択できる
「統計-記述統計」で「項目を削除したときの尺度」にチェックを入れておくと
信頼性の「足を引っ張っている」項目を見つける際に便利
具体的なメニュー画面はこちら
注意
- 逆転項目は逆転済みの項目得点を用いること(逆転項目の作り方)
- 因子分析などで複数の因子が得られて下位尺度を構成した場合は,下位尺度ごとでの信頼性係数を求めるのが基本
回転前第I因子に負荷量が高く,尺度全体としても内的一貫性が想定されるのなら,尺度全体の信頼性を見る,という場合なくはないが.....
なお信頼性分析は,SPSS8まではProfessonalオプションがないと使えない。9.0からBaseに入った
[コマンドシンタックス]
RELIABILITY
/VARIABLES=v1 to v4
/FORMAT=NOLABELS
/SCALE(ALPHA)=ALL/MODEL=ALPHA
/SUMMARY=TOTAL .
なお,SPSSが使えない環境の場合の緊急避難用にMicrosoftExcel上で実行する信頼性係数算出のマクロを作成しました。ダウンロードはこちらまで
【おまけ】SASで同じ計算をする場合
参考までにSASでのプログラム例を示します。
DATA TMP;
INFILE 'MYDATA.DATA';
INPUT NO SEX V1-V4;
SUM=V1+V2+V3+7-V4;......GP分析用の合計点
RUN;
****ここまではデータ読み込み部分:システムによってファイルの指定方法は異なる;
****度数分布*******;
PROC FREQ DATA=TMP;
TABLES V1-V4;
RUN;
****平均と標準偏差****;
PROC MEANS DATA=TMP;
VAR V1-V4;
RUN;
****四分位数**********;
PROC UNIVARIATE DATA=TMP;
VAR SUM;...出力中のQ3,Q1がそれぞれ75,25パーセンタイル点
RUN;
*****一旦上の出力を見てから********;
DATA TMP2;
INFILE 'MYDATA.DATA';
INPUT NO SEX V1-V4;
SUM=V1+V2+V3+7-V4;
SUM1=V2+V3+7-V4;
SUM2=V1+V3+7-V4;
SUM3=V1+V2+7-V4;
SUM4=V1+V2+V3;
FLAG=.;
IF SUM LE 9 THEN FLAG=1;
IF SUM GE 15 THEN FLAG=2;
RUN;
*****t検定(GP分析);
PROC TTEST DATA=TMP2;
CLASS FLAG;
VAR V1-V4;
RUN;
****項目得点と尺度得点の相関(V1~V4まで繰り返す);
PROC CORR DATA=TMP2;
VAR SUM1 V1;
: : : :
PROC CORR DATA=TMP2;
VAR SUM4 V4;
****信頼性係数;
PROC CORR DATA=TMP2 ALPHA NOMISS NOCORR;
VAR V1-V4;
RUN;
***因子分析;
PROC FACTOR DATA=TMP2 METHOD=P PRIORS=SMC ROTATE=VARIMAX;
VAR V1-V4;
RUN;