対応のない3つ以上のカイ二乗検定
※Categoriesオプションが必要です
(例1)期待度数が等しいとき
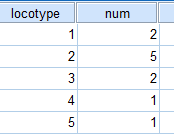
11人に最も好きな蒸気機関車の形式を選択してもらったところ下表のようになった。
機関車の形式間での選択数の差は見られるか?
| 形式 | C54型 | C50型 | C12型 | D62型 | 2120型 |
| 分類番号 | 1 | 2 | 3 | 4 | 5 |
| 選択数 | 2 | 5 | 2 | 1 | 1 |
(例2)カテゴリごとの期待度数を設定するとき
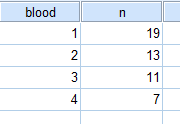
日本人の血液型の出現率はおおよそ,A型40%,B型20%,O型30%,AB型10%である。
ある会社の管理職の人数は,A型19人,B型13人,O型11人,AB型7人であった。
血液型による違いは見られるか。
| 血液型 | A型 | B型 | O型 | AB型 |
| 分類番号 | 1 | 2 | 3 | 4 |
| 管理職人数 | 19 | 13 | 11 | 7 |
※カテゴリを示す変数(分類番号)は必ず数値型にすること。文字型では計算できない。
- データの形式
ローデータから集計データを作成する場合はこちら
例1
例2
- データ-ケースの重み付け を開き
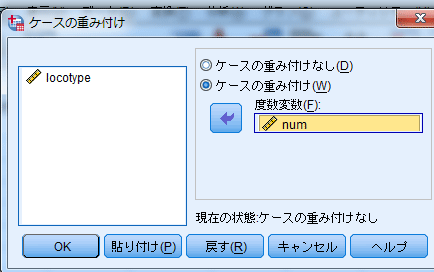
- 「ケースの重み付け」に検定したい度数を設定して[OK]
- 分析-ノンパラメトリック検定-過去のダイアログ-カイ2乗

- 例1の場合:検定変数リストに,カテゴリ分類基準となる変数を指定する。
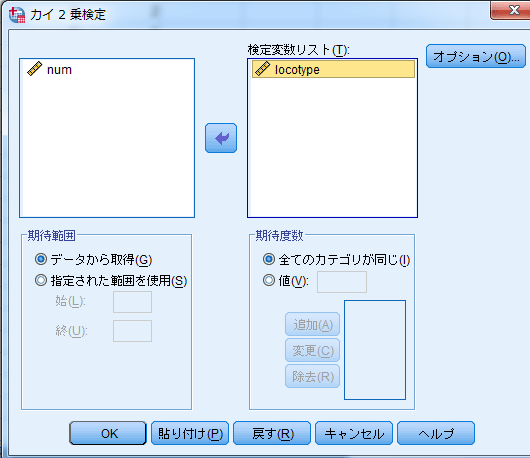
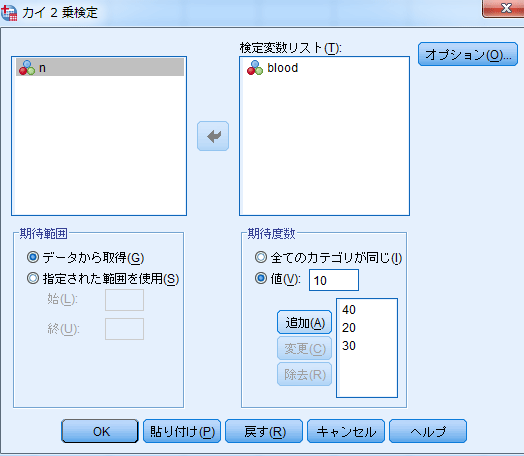
- 例2の場合:検定変数リストに,カテゴリ分類基準となる変数を指定する。
期待度数欄の「値」欄に期待確率を入力し「追加」する。
入力した順がカテゴリの順序となる。
例では分類変数1に40,2に20,3に30,4に10と設定される)。
なお同一比率であれば数値が異なってもよい。たとえば「40 30 20 10」ではなく「4 3 2 1」と入力しても結果は変わらない。
- 必要に応じてオプションを指定し[OK]
- 検定統計量の欄にカイ二乗値が出力される
例1

例2
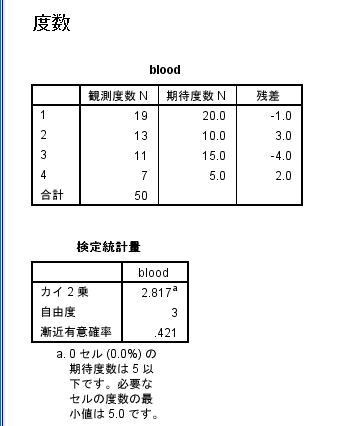
※ケースの重み付け設定は,計算修了後も有効なままなので,別の計算をする際には,必ず設定解除(重み付けなし)に戻しておくこと。また検定する変数(度数の部分)を変更する場合も,ふたたび「ケース重み付け」をやりなおす。
※多重比較を行う場合は2項間の対比較を行いRyan法による名義水準を用いる。
この場合は不要なデータを削除して計算する。
ローデータから集計データを作成する
「データ」メニュー
「グループ集計」を選択
「ブレーク変数」にグループを分ける変数を設定
「集計変数」の「ケースの数」にチェック
「保存」で「集計変数のみを含む新しいデータファイルを作成する」
トップへ